
テキスト |
ここではテキスト表示に関連する実装について解説します。
表示の仕組み
テキスト表示はグラフィック表示とともにGPUを使用することでCPUの負担を減らすような実装をしています。以下に機能ブロックの概略図を示します(一部テキストとは関係ない表示全般に関連する機能も書かれています)。
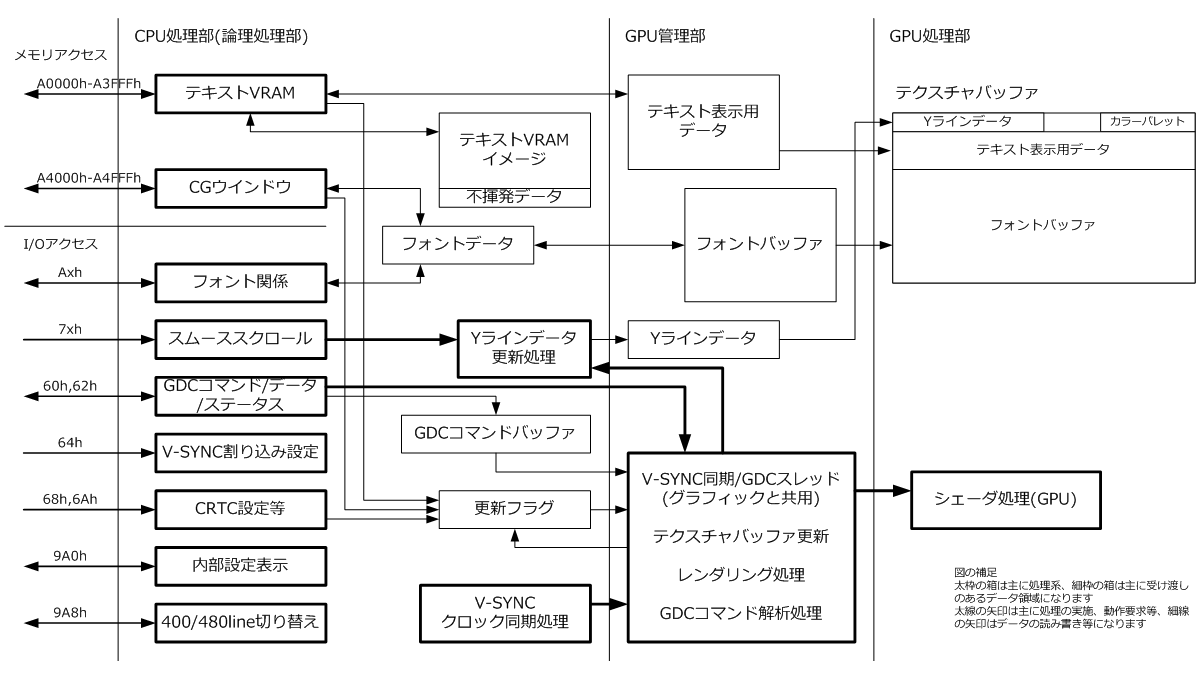
機能ブロックは大きくCPU処理部とGPU管理部に分かれます。これは実装における共通部とOS依存部の切り分けとほぼ同じになります(データ領域の配置は若干違っています)。
CPU処理部ではテキストV-RAMへのアクセスやI/Oアクセスの受け口として機能し、実際の処理の大半はGPU管理部のスレッドによって行われます。
スレッドの起動要因は定周期で発生するV-SYNCに同期したタイミングと、GDCのコマンド処理要求になります。このスレッドではテキスト処理だけでなくグラフィック処理も行いますが、本項ではテキスト関係の機能についてのみ記述します。
●関連ソース
textShader.fx
videom.c
video_win.cpp(video_osx.m)
テキストV-RAMの構成
テキストV-RAMへのメモリ書き込みは処理関数で受け、2種類のデータ構造に書き込みを行います。一つは書き込まれたデータそのままの内容で、テキストV-RAMからの読み出しが行われたときにはこのデータを返します。もう一つは書き込まれたデータをGPUでレンダリングする際に都合のよいデータ構造(図中のテキスト表示用データ)へ変換して格納します。以下にテキストV-RAMとテキスト表示用データの関係を示します。
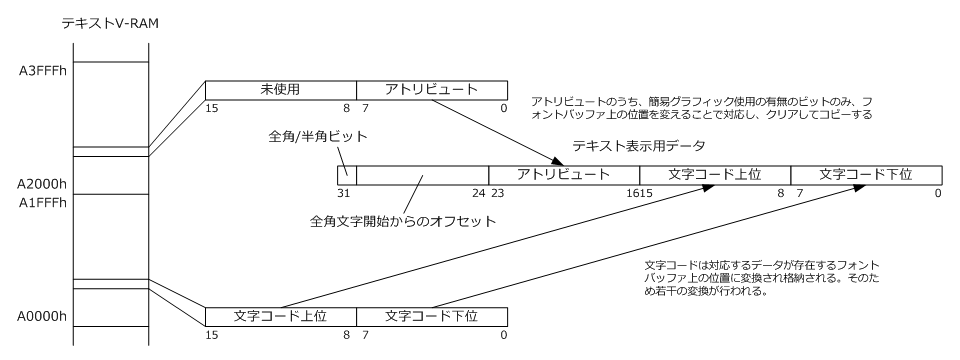
まずテクスチャバッファへ格納するにあたり都合のよいデータサイズは32ビットなので、アドレスが離れている文字コードとアトリビュートを集約します。集約にあたり、文字コードはフォントバッファ上の対応するフォントデータの位置に変換して格納します。余っている8ビットの領域には文字コードが全角か半角か、全角コードの場合文字の左半分を表示するのか右半分を表示するのか判断する情報を格納します。
全角コードは、行頭または直前の文字に半角コードを表示した場合は左半分を表示し、次に続く表示領域には対応するアドレスの文字コードの内容に関わらず直前に表示した全角の右半分を表示します。このような表示条件があるため、全角コードの表示にあたりの左半分なのか右半分なのか、さらにいうと、右半分を表示する場合は参照する文字コードの位置も変える必要があるため独自の管理が必要になってきます。
Yラインデータ
テキスト表示用データはテキストV-RAMの内容をベースにして作成していますが、このほかにYライン毎に用意するデータがあります。これは縦軸に対してキャラクタ単位での先頭位置や、キャラクタ内での何ライン目を表示するかやカーソルブリンクさせる範囲などを格納します。以下にデータを図示します。
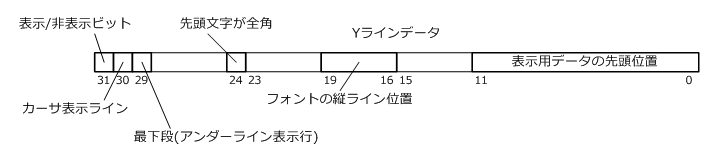
キャラクタ単位の情報としては、GDCのPITCHコマンドやSCROLLコマンドによって変わりうるテキスト表示用データの先頭位置と、先頭文字が全角か半角かの判別情報を格納します。キャラクタ内のYライン位置毎のデータとしては、ポート7xhで設定するスムーススクロールと、GDCのCSRFORMコマンドで変化しうる対応ラインの表示/非表示、カーサ表示ライン、アトリビュートでアンダーラインが指定されたときに表示されるラインの位置かどうかの判定情報を格納します。
フォントバッファとフォントデータ
フォントバッファはメインメモリとテクスチャバッファで二重に持っています。実機の場合、「テキスト画面が乱れるがいつでも読み出し可能」と「表示は乱れないが垂直同期期間中のみ読み出し可能」のいずれかの読み出し方法がありますが、フォントデータの読み出しに伴いテクスチャバッファから直接データを読み出そうとした場合、若干時間がかかることとレンダリング中に読み出しを行うとレンダリングが終了するまで遅延させられるため、実機の挙動をうまく再現できませんそのため、読み出しはメインメモリから行うようにし、外字データの変更に伴いメインメモリ側が更新されたときにはその後のレンダリングの直前にメインメモリからテクスチャバッファへコピーして同期をとります。
このような実装にしているため、エミュレータでは実機と異なりテキスト画面が乱れることなく任意のタイミングでフォントデータを読み出し可能になっています。
フォントデータはポートA1h、A3hにより指定された1文字分のデータをフォントバッファからコピーした内容になります。
スレッドの動作
表示のためのスレッドはテキスト表示とグラフィック表示と共用になっています。通常はイベント待ち状態で待機していて、垂直同期の周期タイミングとGDCコマンド/データが設定されたときにイベントにより起動します。垂直同期のタイミングでは、まず更新フラグが設定されている場合、対応するデータをメインメモリからテクスチャバッファへ書き込みます。書き込みにあたっては変更した領域のみを部分的に更新するのと、領域全体を更新するのでは速度的な差がほとんどないことから領域全体を書き換えるようにしています。
次に、テキストおよびグラフィックのテクスチャバッファの更新処理が終わったらテキストのレンダリング、グラフィックのレンダリング、スケーリングを順に行い画面表示を行います。
もう一つの機能として、GDCコマンドの実処理を行います。ポート60h、62hにデータが出力されたらデータがキューイングされスレッドへイベント通知されることによりスレッドが起動します。
テクスチャバッファとレンダリング
レンダリング時に表示ソースとして使用するテクスチャバッファには、前述のようにソフトウェアで作成したYラインデータ、テキスト表示用データ、フォントバッファと色指定のためのカラーパレットにより構成されています。全データを格納するためにテクスチャバッファのサイズは1024x134ピクセルになっていますテクスチャバッファ内のフォントバッファの構成について補足すると、1文字のデータサイズは半角フォントは16バイト、全角フォントは32バイト必要になりますが、テクスチャ1ピクセル分のサイズは(CPU側から見て)32ビットになるため、半角は4ピクセル、全角は8ピクセルにフォントデータを格納しています。テクスチャバッファの横サイズは1024ピクセルのため横1ラインに半角は256文字、全角は128文字格納していることになります。
テキスト表示のレンダリングはやや複雑になっています。
まずバーテックスシェーダですが、こちらは画面の4隅を頂点とした矩形を表示領域全体に表示するだけの処理になります。
ピクセルシェーダのほうですが、描画するピクセル(x,y)が指定されたら、xからは左端からの文字数と文字フォントの何列目のラインを表示するのかを算出します。yからは対応するYラインデータを参照します。Yラインデータとx座標から参照するテキスト表示データが特定できます。ここで、テキスト表示データを参照するのにあたりいくつかの条件で特定した位置の一つ前のデータを参照する必要があります。
一つは表示位置が全角データの右半分のときで、このときは文字コードとして前の文字データを参照します。もう一つはアンダーラインの表示に関してで、アンダーラインは4ピクセル右にずれて表示する必要があるため、半角文字の横幅8ピクセルのうち前半4ピクセルのアンダーライン情報は前の文字の情報を参照する必要があります。
テキスト表示データが特定されたら、対応するフォントデータの特定、Yラインデータと、x座標からフォント内の位置を特定し、アトリビュートとカラー情報から最終的にピクセルに書き込む内容を決定します。
かなり大雑把に書きましたが、テキスト表示をシェーダ言語で再現するに当たって上記のような流れで処理を行っています。
ここでシェーダ言語を使うにあたり、C言語では通常意識しないようなところで非常に注意して実装しなければならないポイントについて簡単に記述しておきます。(ここは公開後もかなり悩まされたところなので...)
まず、シェーダ言語がC言語と異なる主なところをあげておくと、
-
・ピクセルシェーダで指定される座標やテクスチャデータから読み出したデータは0.0~1.0に正規化されたデータである
・正規化されたデータはGPUに依存のデータ幅で丸め処理がされている
・論理演算が使用できない
・分岐は使用できるが、あまり分岐を多用するとコンパイルが通らなかったり通っても期待通り動作しない
ここで注意しないといけないのは、例えばテクスチャデータの場合に正規化されたデータを255倍すれば元に戻るかというと必ずしもそうはならないということです。分数で表記すれば正確な値ですが、実際には浮動小数点に変換されておりその際には丸め処理が行われています。丸めが行われるというとは小数点以下何ビット目かで繰り上げまたは繰り下げが行われているということになります。繰り上げは大きな問題にはなりませんが、繰り下げの場合は例えば200が正規化された値が0.78431372549だった場合、255倍しても199.99999という値にしかなりません。(やっかいなのは0~256の範囲が正規化されていればコンピュータ的にはきりがよいのですが、実際には0~255が正規化されているため、ほとんどのケースで丸め処理された数値になります)
シェーダ言語では論理演算が出来ないため、その代わりに乗算や整数部のみ抽出などの演算を組み合わせて該当ビットがセットされているかどうか判断しますが、前述のように199.99999のような値だと、整数部は199になってしまい期待と異なる結果になります。そのため正規化されたデータを整数に戻す際には255を乗算した上で意図しない繰り上げが起きない程度の補正値を加算する必要があります。
次に、論理演算が出来ないことに対する代替処理の例を以下に示します。
たとえば、参照する値が16進数でvalue=0xe0のときに、bit6の値がセットされているかどうかをチェックする場合、C言語では
if((value & 0x40) != 0)といった感じで判定しますが、シェーダ言語では論理演算が使用できない、かつ正規化された浮動小数点値で扱うためvalueは0.87843137254902のように浮動小数点として扱う必要があります。
この区切りの悪い数値は、前述のように演算誤差の原因となります。これを防ぐために計算前に計算後の結果が0.5以下に相当する値をあらかじめ加算しておきます(この値の適切な値をどの辺にするかは微妙なのですが、255倍したときに整数値に期待値以上に繰り上がりが起きない値、たとえば0.5/255程度であれば演算誤差の補正ができると思います。なお実際の実装では主に0.25/255.0を使用しています)。
実際の計算目標としてはチェックしたいビットを、セットされていたら1.0されていなかったら0.0になるようにします。 まず、チェックしたいビットより上位にあるビットを排除するために、剰余を計算します。
剰余の関数はfmodで具体的な計算としては、
value2 = fmod(value * 255.0 + 0.25, 128.0);この結果、value2にはbit6より上の要素が排除されるので次に最終的な目標値である、bit6セットされていたら1.0されていなかったら0.0にする計算ですがこれには、そのまま計算できる関数があります。
value3 = step(0.5, value2);step関数は、第2引数の値が第1引数の値より大きい場合は1.0、小さい場合は0.0を返す関数です。
最後にこの値の使い方ですが、アトリビュートの場合対象ビットの状態によって該当するピクセルに色をつけるか、透明のままにするかという条件になることがほとんどのため、この値をアルファ値を含む文字色に乗算し色設定するようにすれば、条件分岐を必要とせずに0.0なら表示しない、1.0なら表示するという処理に出来ます。
pixelcolor = color * value3;value3が1.0の場合colorで指定された色になり、0.0の場合は透過色が指定されます(グラフィック面が表示対象になる)。
文字コードに対応するフォントデータの位置計算も概念的には同じようなことをしています(こちらは論理演算が必要になってくるわけではないのでもっと単純です)。
テキスト表示にシェーダを使用することに関する所感
エミュレータ作成にあたり作ってみたかった実装の一つが、表示系にプログラマブルシェーダを使用してGPUに処理を負担させるということで、一応期待通りの実装が出来たと思っていますが、とはいえ作成当初考えていたとおりに行かなかったり、予想外だったりしたことがあったのでここに書き留めておこうと思います。・演算誤差の吸収
これには最後まで悩まされました。もしかしたら現在でも正しく表示されていないGPUがあるかもしれません。
通常使用するような3D表現であれば見た目の際はほとんどないような演算誤差でも、文字通り白黒はっきりとしたビットマップ表示に使用するときには注意して実装する必要があると感じました。
・プログラム規模の問題
テキスト表示を行うシェーダのプログラムはそこそこ大きくて、一度演算の効率化のため大幅にロジックを作り直しましたがそれでもまだ大きい感じです(バージョン0.2.5.0ではps_4_0で109 instruction slots、ps_2_xで129 instruction slotsになっています)。
プログラム規模が大きいことで問題になるのはDirectX10に対応していない世代のGPUへの対応です。実際のところDirectX9世代のGPUでは十分なパフォーマンスが出ないのが実情でそこの部分を解消するのは難しいのですが、とはいえ少しでもましな動作をさせられないかというところでこの規模の問題が出てきます。
DirectX10に対応していないGPUに対してDirectX10を使用するとしてハンドラをオープンするとWARPドライバというハードウェアアクセラレーションを使用せずすべての機能をソフトウェアで実現するドライバのハンドラを取得します。この場合GPUが持つ本来の性能を遙かに下回る性能でしか動作しないため、こうしたGPUではDirectX9の機能で動作させるほうがよいのですが、今度はシェーダプログラムの規模がDirectX9の上限を超えるサイズのためそのままではDirectX9では動作させられません。結局DirectX10用のプログラムとは別に同じ機能を3回のレンダリングに分けて実現する3つのプログラムを起こしてDirectX9対応をしています(3分割した状態でそれぞれの規模は、63、60、52 instruction slotsになっています。計算総量は大分増えてしまっています)。こうすることでDirectX9世代のGPUでもハードウェア機能を使用できるようになったのですが、トータルの演算量は増えていますしもともとこの世代では重いプログラムとなってしまっているため期待したパフォーマンスが出てくれていないのが実情です。
・データの2重化
シェーダを使用することで、テクスチャバッファに書き込むために用意するメインメモリ側の領域と、テクスチャバッファと常に2重にデータを持つ必要があるためメモリ効率は悪いような気がします。特にフォントイメージは当初テクスチャバッファ側にのみ持って必要に応じテクスチャバッファからデータを引き出すように考えていましたが、それでは実用にならないため結局すべてのデータがメインメモリ側と2重化されています。
とはいえ、実機を考えた場合周辺のデバイスはCPUとは独立して動いているものですし、近年のGPU性能の向上やCPUの低クロック多コアの流れをみるに、GPUに表示処理の負担を追い出しCPUには本体のエミュレーションに時間を割くという考え方は理にかなっていると考えています。面倒な計算を強いられることにはなりますがちゃんと動くところまで面倒が見られれば実機の再現という点ではなかなかよい使い方ではないかと思います。